NeuRewriter[2019]Learning to Perform Local Rewriting for
Combinatorial Optimization
Zhen Tong 120090694
Paper:
This paper is written by Xinyun Chen (A very excellent researcher now in DeepMind), and Yuandong Tian(Facebook AI Research).
In this paper, they are focused on how to determine when and where these heuristics should be applied, and how to prioritize them, which is very time-consuming.
To address this problem, previous studies have used neural networks to predict a complete solution from scratch, giving a complete description of the problem. While this avoids searching and tuning, direct prediction can become difficult when the number of variables increases
To solve this problem, they directly learn a neural network-based strategy by iteratively rewriting local parts of the current solution until they converge. Inspired by the structure of the problem, the strategy is broken down into two parts:
- the region-picking and the rule-picking policy
- and is trained end-to-end with reinforcement learning, rewarding cumulative improvement of the solution.
Given current state (That is, the solution to the optimization problem),Let's first run the region selection strategy , to get a region ,Then use rules to select policies 。 Apply the probability distribution to partial solutions. Once the partial solution is updated, we get an improved solution , And repeat the process until convergence.

Detail
Neural Rewriter Model
下面,我们将介绍重写模型的设计,即NeuRewriter。我们首先提供模型框架的概述,然后介绍不同应用程序的设计细节
4.1 Model Overview
Score predictor
给定状态,Score predictor为每一个计算一个分数,它衡量重写的好处。高分表明重写是可取的。注意Ω(st)是一个问题相关的区域集。
For expression simplification, Ω(st) includes all sub-trees of the expression parse trees
for job scheduling, Ω(st covers all job nodes for scheduling; and for vehicle routing, it includes all nodes in the route.
Rule selector.
给定st[ωt]要重写,rule-picking policy在整个rule set U 中预测的概率分布 ,选择应用规则。
4.2 Training Details
rewriting sequence in the forward pass:
Reward function
Q-Actor-Critic training
同时训练region-picking 策略和rule-picking策略
通过softmax
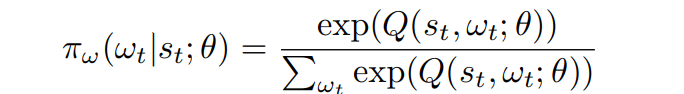
The loss function of the region selector is
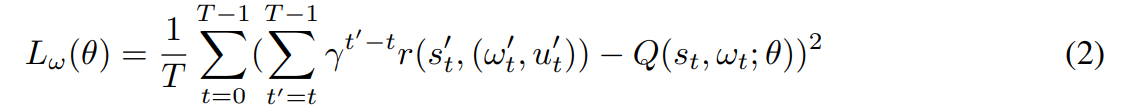
T is the length of the episode.
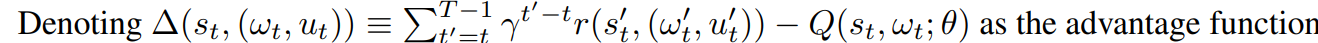
the loss function of the rule selector is
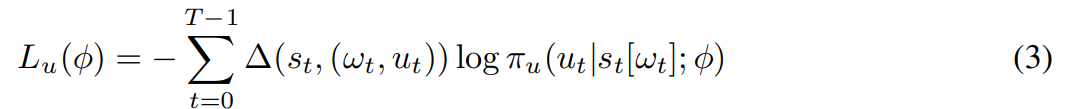
The overall loss function is:, α is a hyper-parameter.
(a)expression simplification;(b)作业调度;(c)车辆路径
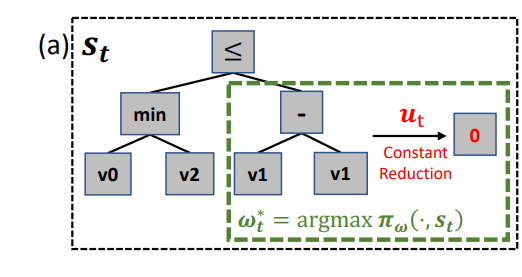
在(a)中,是表达式解析树,其中每个正方形代表树中的一个节点。集合包含了每棵在非终端节点上生根的子树,区域选取策略从该子树中选择进行重写。然后,规则选择策略预测出一个重写规则,然后重写子树,得到新树。
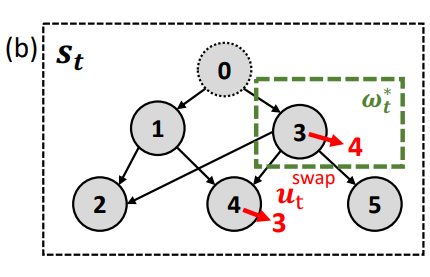
(b)中,是job问题的依赖图表示。每个索引大于0的圆代表一个作业节点,节点0是一个额外的表示机器的节点。图中的边反映了作业的依赖性。区域选择策略从所有作业节点中选择一个作业重新调度,规则选择策略为选择一个移动动作,然后修改得到一个新的依赖图。
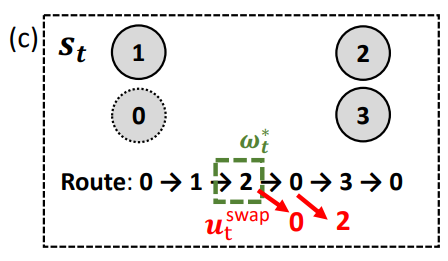
(c)中,为当前路,为选择改变访问顺序的节点。节点0为车辆段,其他节点为有一定资源需求的客户。区域选择策略和规则选择策略的工作类似于作业调度策略
Application
在下面的部分中,我们将讨论重写方法在三个不同领域的应用:表达式简化、在线作业调度和车辆路由。在表达式简化中,我们使用定义良好的保持语义的重写规则集最小化表达式长度。在在线作业调度中,我们的目标是减少作业的整体等待时间。在车辆路径设计中,我们的目标是使总行程长度最小化。
5.1 Expression Simplification
我们首先将该方法应用于表达式简化Halide中的表达式,这是一种用于高性能图像处理[39]的领域特定语言,在谷歌的多个产品(如YouTube)和Adobe Photoshop中被广泛大规模地使用。简化Halide表达式是整个代码优化的重要一步。为此,为表达式实现了一个基于规则的重写器,该重写器使用手工设计的启发式仔细调整。重写器中考虑的表达式的语法在附录A中指定。
在研究了基于规则的重写器中的重写模板后,我们发现大量重写模板列举了一个上移规则的特定情况,它先延长表达式,然后缩短它(例如,min/max展开)。与梯度下降法中的动量项进行连续优化相似,该规则用于避免局部最优。然而,它们只应在初始表达式满足某些先决条件时应用,这通常是由手工设计指定的,这是一个繁琐的过程,很难推广。通过观察这些限制,我们假设神经网络模型有可能比基于规则的重写器做得更好。我们只保留core rewriting rules,去掉所有不必要的pre-conditions,让神经网络决定应用每个重写规则的时间和内容。这样,神经重写器比基于规则的重写器具有更好的灵活性,因为它可以从数据中学习这样的重写决策,并且有能力发现基于规则的重写器中不包括的新颖重写模式。
Ruleset
我们从Halide重写规则集中合并了两种模板。第一种是简单规则(如v−v→0),第二种是去掉人工设计的不影响重写有效性的前提条件后的上坡规则。这样,规则集具有|U| = 19类构建
Model specification
我们使用表达式解析树作为输入,并使用[46]中设计的N-ary tree - lstm作为输入编码器来计算树中每个节点的嵌入。score predictor和rule selector都是完全连接的神经网络,以LSTM嵌入作为输入。更多的细节可以在附录C.1中找到。
5.2 Job Scheduling Problem
Notation
假设我们有一台拥有D种资源的机器。每个作业j指定为,其中d维向量表示资源类型d所需的部分,为到达时间步长,为持续时间。另外,我们定义为计划的开始时间,为完成时间。
我们假设在整个作业执行过程中,资源需求是固定的,每个作业必须连续运行直到完成,并且不允许抢占。我们采用在线设置:有一个等待的作业队列,最多可以容纳W个作业。当新作业到达时,可以立即分配它,也可以将它添加到队列中。如果队列已经满了,为了给新作业腾出空间,需要立即调度队列中至少一个作业。我们的目标是为每一项工作找到一个时间表,这样平均等待时间尽可能短。
Ruleset
重写规则集是重新调度一个作业,并在另一个作业之后分配它结束或到达时间。改写步骤请参见附录B.2。重写规则集的大小为|U| = 2W,因为每个作业只能分别与最多W个前作业和后作业切换调度顺序。
Representation
我们将每个调度表示为一个有向无环图(DAG),它描述了不同作业的调度时间之间的依赖性。具体来说,我们将每个作业表示为图中的一个节点,并添加一个额外的节点来表示机器。如果一个作业vj被调度在到达时间Aj(即Bj = Aj),那么我们在图中加入一条有向边<v0, vj >。否则,必须至少有一个作业使(即作业从作业之后开始)。对于每一个这样的作业,我们在图上加上一条边。
6 Experiment
我们将在本节中展示评估结果。为了计算推理时间,我们在同一个服务器上运行所有算法,该服务器配备2个Quadro GP100 gpu和80个CPU核。神经网络评估只使用1个GPU,搜索算法使用4个CPU核。我们将搜索算法的超时设置为每个实例10秒。我们评估中的所有神经网络都是在PyTorch[38]中实现的。文章中处理的问题规模比较小,在50-100个城市之间。